This post is the fourth in a series produced for a Harvard Kennedy School field class on innovation in government. Our team is working with the Census Bureau. You can read about our project here, our experience interviewing and engaging Census users here, and see the results of our user research here.
Two weeks ago, we shared how we arrived at a key insight from our user research. This week, we translated our key insights into a low fidelity prototype – check it out! Driven by our user research, we revisited our problem statement:
How might we improve user experience—search, retrieval and incorporation—of U.S. Census data, particularly income distribution data?
We ultimately decided to prototype a webpage about Income Inequality in America, the precise product we promised ourselves at the outset we would avoid! Here’s how we arrived at this unlikely solution:
We brainstormed potential solutions. We conducted an unconstrained brainstorming session, assessing each and every idea proposed. To structure this process, but also allow for creativity, we examined other industries where users need assurance they are using a product correctly, one of the main concerns Census users raised. How did these industries address the need for assurance? How do they build trust?
One industry we discussed was online shopping. Online shopping websites assure customers that they are purchasing an item that will fit, without the customer trying on the item. Companies can do this because they provide customer service representatives who answer questions and respond to concerns live. They also provide photographs, product dimensions, and user reviews to increase transparency and reduce uncertainty.

Our team brainstormed a list of strategies that companies use to build trust and assurance with their customers.
We refined our list of ideas. Following our ideation session, we refined our list of potential prototypes. Some ideas that surfaced were:
Census StackExchange, a curated Q&A service for data;
Short summaries for data sets (a “peak inside”); and
A Twitter campaign where users could post their questions with the hashtag #AskAlexandra (one of the Census Data Dissemination team members).
In addition, we discussed our approach and ideas with three experts: Ben Willman, Jeff Chen, and Jeff Miesel. They helped us realize that we had real power as a group of Harvard students to take risks that the U.S. Census Bureau could not take. With this in mind, we further refined our list of potential prototypes.
We also visited the U.S. Census Bureau in Suitland, Maryland to assess the feasibility of our prototype ideas and receive feedback. While there, we developed a deeper understanding of the various work streams, projects, and conversations happening at the Bureau. These meetings brought us a key insight that would help us chose our prototype: Census is already working on addressing the key insights from our user research.

Left to Right: Peter Willis (HKS ’17), Logan Powell (U.S. Census Bureau), Rebecca Scharfstein (HKS/HBS ’18), Trudi Renwick (U.S. Census Bureau), and Alexandra Figueroa (U.S. Census Bureau).
As we learned about these projects, we tested whether the U.S. Census Bureau was incorporating the perspective of users outside of the Bureau, like those we had spoken to in our research. Although the team has adopted an agile approach, it seems that user testing is limited. Too often, Census focuses on “power stakeholders,” important internal stakeholders.
Encouraged by Erie Meyer, we saw the hesitation to engage outside users as an opportunity. We realized we could develop a prototype that complements projects already underway at the Bureau but is grounded in a user-centered approach. Our prototype could act as blueprint for the U.S. Census Bureau to increase user involvement in its projects.
We decided on a prototype and got to work. We decided to develop a low fidelity webpage, a re-imagination of what the current income inequality topic page on the Census website could look like. We hope that our webpage will provide a more streamlined user experience, and we plan to test it alongside the current page.
As far as we could tell, no project at the U.S. Census Bureau has a mandate to re-imagine the website layout and structure. Perhaps it’s too risky or radical. However, if we can prove that an alternative website structure is better for users, we may be able to encourage the Bureau to invest resources in a front-end development project.
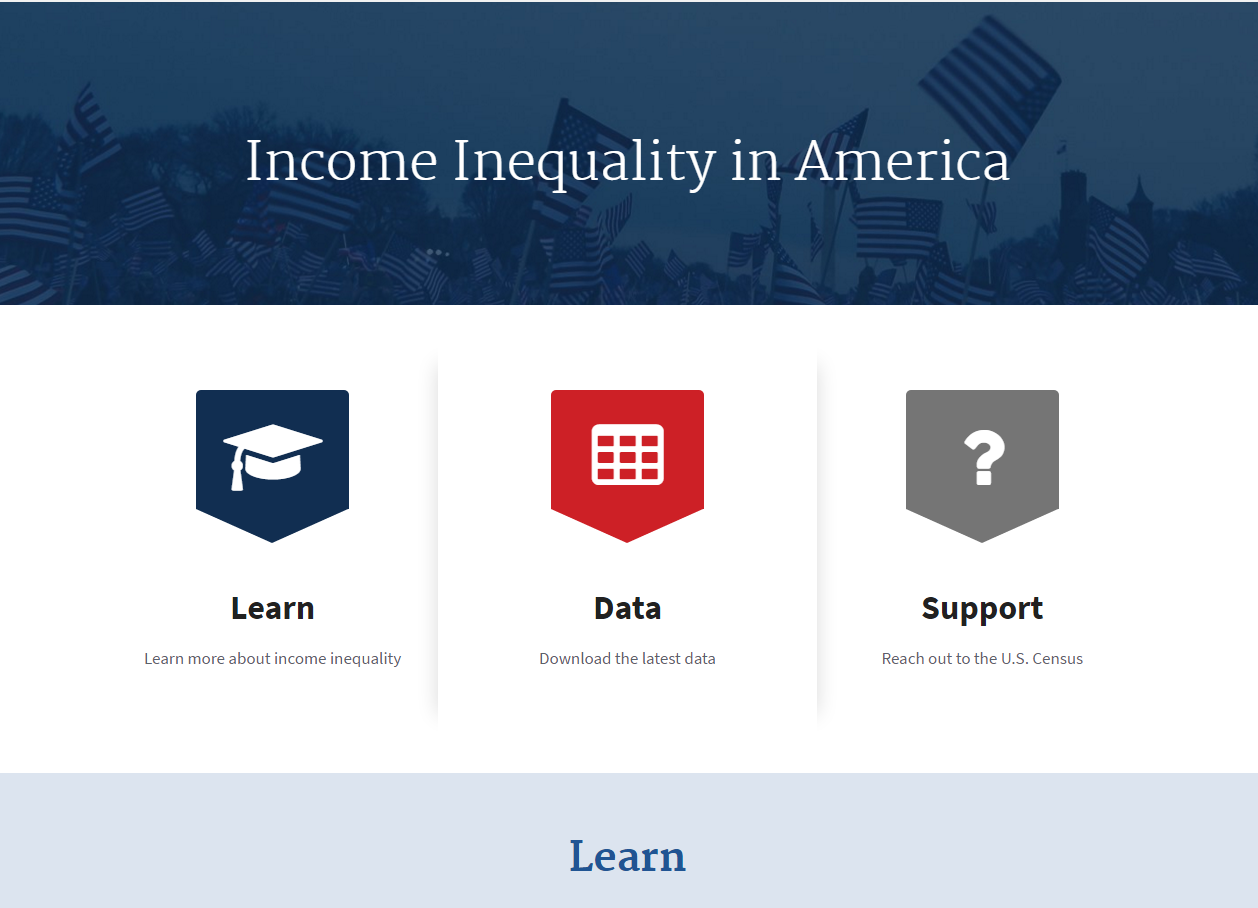
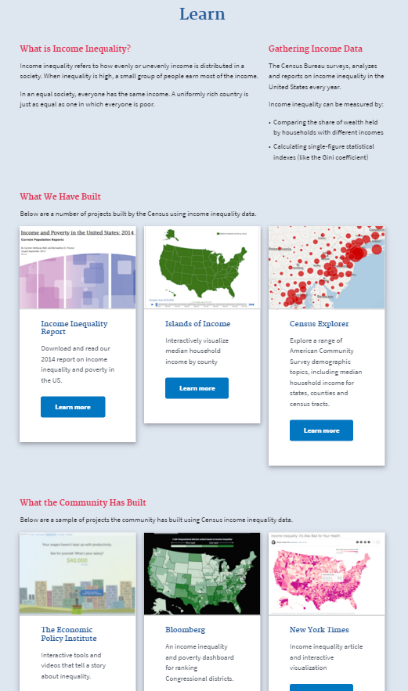
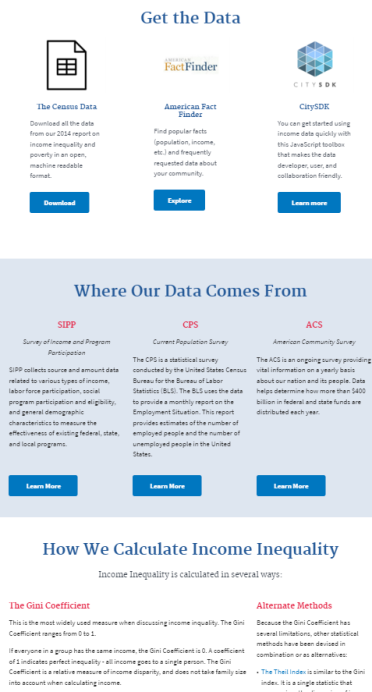
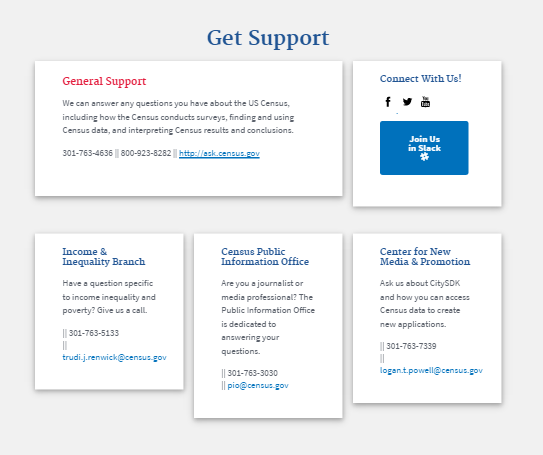
Our prototype contains three main sections: learn, data, and support.
Learn. In the “learn” section, we provide a definition of income inequality, show how the Census collects income inequality data, and offer a selection of tools developed by the Census and the community. These resources aim to address the insights that data can overwhelm and deter users and that users want assurance they are using data properly.
Data. In the “data” section, we identify where users can get income inequality data, describe where the data comes from, and explain how the Census calculates income inequality. As with the “learn” section, these features address user concerns around the overwhelming quantity of Census data and the uncertainty that data is being used properly.
Support. Our final section—the “support” section—provides various avenues to obtain personal support should a user have difficulty accessing or understanding Census’ data. This directly addresses the insight that users value personal support.
Next up: We will be conducting user testing on our prototype in the coming weeks to see if we have effectively addressed the key insights from our user research. If you are interested in providing feedback, tweet at us—@beccascharf @willispb @NidhiBadaya @whosluciano—or e-mail us at innovategovernment@gmail.com.
Luciano Arango, Nidhi Badaya, Aaron Capizzi, Rebecca Scharfstein, Peter Willis